

本記事はアフィリエイト広告(PR)を含みます。
最終更新:2026年6月11日|情報は執筆時点のものです。

この記事のポイント(結論)
✅コーディング・推論・長文処理ではClaude Fable 5が頭ひとつ抜けている
✅汎用性・マルチモーダルではGPT-5.5が強い
✅コスト重視・Google連携ではGemini 3.1 Proが有利
✅1つのモデルで全部解決しようとするより、用途で使い分けるのが2026年の正解
3モデルの基本スペック比較
| 項目 | Claude Fable 5 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|
| 開発元 | Anthropic | OpenAI | |
| リリース | 2026年6月 | 2026年2月 | 2026年1月 |
| コンテキスト | 100万トークン | 100万トークン | 200万トークン |
| 入力料金 | $10/1Mトークン | $5/1Mトークン | 約$3/1Mトークン |
| 出力料金 | $50/1Mトークン | $30/1Mトークン | 約$15/1Mトークン |
| 画像入力 | ✅ | ✅ | ✅ |
| 音声入力 | ❌ | ✅ | ✅ |
| 画像生成 | ❌ | ✅ | ✅ |
ベンチマーク比較
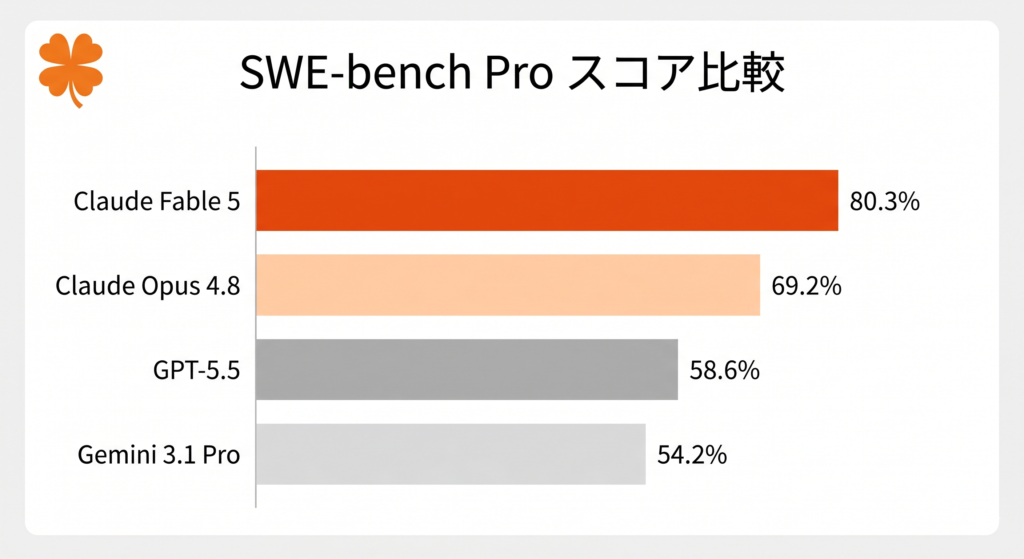
実際の開発・業務タスクで使われる主要ベンチマークで比較します。
| ベンチマーク | Claude Fable 5 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Pro(コーディング) | 80.3% | 58.6% | 54.2% |
| GDPval-AA(知識業務) | 1932点 | 1769点 | 1314点 |
| GPQA(博士レベル科学) | 非公開 | 最高水準 | 非公開 |
| 日本語推論(Artificial Analysis) | 93点(同率首位 | 高水準 | 93点(同率首位) |
SWE-bench Proはコーディング性能を測る代表的な指標で、Fable 5は80.3%と他モデルを約21ポイント引き離しています。一方、博士レベルの科学的推論(GPQA)ではGPT-5.5が強く、日本語推論ではGemini 3.1 Proも高い評価を得ています。
※ GPQAのFable 5・Geminiスコアは執筆時点で非公開。
日本語推論は
Artificial Analysis Intelligence Index(2026年1月時点)
のランキングより。
各モデルの強みと弱み
Claude Fable 5の強みと弱み
強み
- コーディング性能が圧倒的。SWE-bench Proで80.3%はライバルに20pt以上の差
- 知識業務・推論・法律・ヘルスケアなど幅広い領域でOpus 4.8を上回る
- 100万トークンのコンテキストで長文処理が得意
- 適応的推論が常時オンで、複雑な問題に強い
弱み
- 料金が最も高い(出力$50/1Mトークン)
- 音声入力・画像生成には非対応
- 高リスク領域(サイバーセキュリティ等)でOpus 4.8へフォールバック
GPT-5.5の強みと弱み
強み
- 音声・画像生成・テキストを統合したマルチモーダル対応が最も充実
- 博士レベルの科学的推論(GPQA)でトップ
- 汎用性が高く、さまざまなタスクにバランスよく対応
- ChatGPT経由で使いやすいUI
弱み
- コーディング性能はFable 5に大きく劣る(58.6% vs 80.3%)
- 出力料金$30/1Mトークンはそれなりに高い
Gemini 3.1 Proの強みと弱み
強み
- 料金が最も安い(入力約$3、出力約$15/1Mトークン)
- コンテキストウィンドウが200万トークンと最大
- Google Workspace・Google検索との連携が強力
- 日本語推論でClaude Opus 4.8と同率首位
弱み
- コーディング性能はFable 5より大きく劣る(54.2%)
- 知識業務(GDPval-AA)でFable 5に大差をつけられている
用途別おすすめモデル
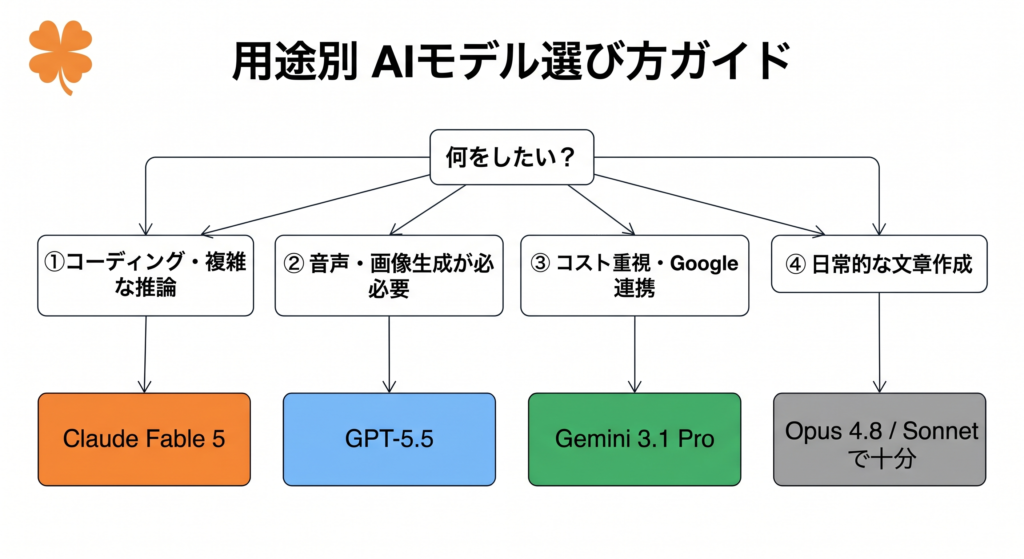
| 用途 | おすすめ | 理由 |
|---|---|---|
| 大規模コーディング・開発 | Fable 5 | SWE-bench Pro 80.3%で圧倒的 |
| 日常的な文章作成・校正 | GPT-5.5 or Gemini | コストパフォーマンスが高い |
| 音声・画像を使う業務 | GPT-5.5 | マルチモーダル対応が最も充実 |
| Google連携・コスト重視 | Gemini 3.1 Pro | 料金最安+Workspace連携 |
| 長文資料の分析・要約 | Fable 5 or Gemini | 大容量コンテキストが活きる |
| 科学・研究分野 | GPT-5.5 | 博士レベル推論でトップ |
| ブログ・コンテンツ制作 | Fable 5 or GPT-5.5 | 推論・文章品質ともに高い |
| せどり・ポイ活の情報収集 | Gemini | Google検索連携が強力 |
料金の実質コスト比較
API料金だけで単純比較するとFable 5が最も高いですが、「同じタスクに何回やり直しが必要か」を考えると話が変わります。
Fable 5は精度が高いため、エラー修正・再試行の回数が少なく済みます。特にコーディングタスクでは、Fable 5の1回の出力でOpus 4.8の2〜3回分の成果が得られるケースがあり、実質コストはそれほど変わらない場合があります。
Claude.aiサブスクプランでの比較(2026年6月時点)
| プラン | Claude Fable 5 | GPT-5.5 | Gemini Ultra |
|---|---|---|---|
| 月額 | $20(Pro) | $20(Plus) | $99.99(AI Ultra) |
| 追加費用 | 6月22日まで無料 | なし | なし |
Claude.aiの有料プランユーザーは6月22日まで追加料金なしでFable 5を試せるので、まず触れてみて自分の用途に合うか確認するのが一番確実です。
セキュリティ・プライバシーの違い
| 項目 | Claude Fable 5 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|
| データ保持期間 | 最大30日 | ポリシーによる | ポリシーによる |
| ゼロデータリテンション | ❌(対象外) | プランによる | プランによる |
| 安全機構 | セーフガード付き | 標準 | 標準 |
Fable 5は安全機構の運用上、最大30日間のデータ保持が必要で、ゼロデータリテンションには非対応です。機密情報を扱う業務では注意が必要です。
まとめ:どれを選べばいい?
1つのモデルに絞る必要はありません。2026年時点では「用途に応じて使い分ける」のが最もコスパが高い選択です。
おすすめの使い分け方
- コーディング・複雑な推論 → Fable 5
- 音声・画像生成が必要 → GPT-5.5
- コスト重視・日常タスク → Gemini 3.1 Pro
まずClaude.aiの有料プランを使っているなら、6月22日まで無料で試せるFable 5から始めるのが最もリスクが低いです。
注意事項・免責
・本記事の情報は2026年6月11日時点のものです。
・ベンチマーク・料金・仕様は変更になる場合があります。必ず各社公式サイトで最新情報をご確認ください。
・ 本記事は投資・購入を推奨するものではありません。







コメント
コメント一覧 (1件)
[…] […]